

If you’re looking for the best PCIe accelerator cards for inference in 2025, I recommend considering options like the Coral Mini PCIe with its low power consumption and compact size, along with high-performance modules like the NVIDIA Tesla A100 for demanding workloads. Other top picks include M.2 Edge TPU accelerators and the Waveshare Hailo-8 for efficient real-time vision tasks. Keep exploring, and you’ll discover more about these advanced accelerators and how they can boost your projects.
Key Takeaways
- The list includes compact accelerators like Coral Mini PCIe and M.2 Edge TPU modules optimized for edge inference.
- High-performance options such as NVIDIA Tesla A100 and Tesla K80 cater to data center and scientific workloads.
- Compatibility varies, with some cards supporting Linux, Windows, and embedded platforms, suitable for diverse deployment environments.
- Power efficiency is emphasized, with many accelerators offering low wattage and high throughput for real-time vision and ML tasks.
- The selection balances size, speed, energy consumption, and application focus, from edge AI to large-scale data center inference.
Coral Mini PCIe Accelerator (G650-04528-01)

If you’re looking for a compact yet powerful PCIe accelerator for edge inference, the Coral Mini PCIe Accelerator (G650-04528-01) is an excellent choice. Its tiny form factor measures just over an inch in each dimension, making it ideal for space-constrained setups. Powered by an ARM-based processor with DDR4 RAM, it delivers impressive performance, supporting up to 4 TOPS with an ultra-low power draw of only 0.5 watts per TOPS. Compatible with Debian Linux, Windows 10, and various architectures, it’s perfect for high-speed inference tasks like vision models, combining efficiency with ease of deployment.
Best For: developers and engineers seeking a compact, high-efficiency PCIe accelerator for edge AI inference in space-constrained environments.
Pros:
- Ultra-low power consumption of just 0.5 watts per TOPS, ideal for energy-efficient deployments
- Compact form factor measuring just over an inch in each dimension, suitable for tight spaces
- Supports popular operating systems and machine learning frameworks like TensorFlow Lite for easy deployment
Cons:
- Limited to a single ARM-based processor, which may restrict multitasking capabilities
- Requires compatible PCIe slots and Linux or Windows environments, potentially limiting use with other OS
- Relatively niche product with a specialized use case, which might require additional integration effort
Dell NVIDIA Tesla K80 24GB PCIe Server GPU (Renewed)

The Dell NVIDIA Tesla K80 24GB PCIe Server GPU is an excellent choice for professionals who need maximum computational power without the expense of a new device. It features 24GB GDDR5 memory, 4992 CUDA cores, and delivers a 5-10x performance boost for scientific computing, machine learning, and data processing. However, it runs extremely hot and requires robust cooling solutions, such as water cooling or active fans. Installation can be complex, involving hardware modifications and driver setup, making it best suited for experienced users. While powerful, it lacks video outputs and is primarily designed for server environments, not typical desktops.
Best For: experienced professionals and tech enthusiasts seeking high-performance, cost-effective GPU acceleration for scientific computing, machine learning, and data processing in server or custom setups.
Pros:
- Offers 24GB GDDR5 memory and 4992 CUDA cores for powerful computation
- Significantly accelerates scientific, machine learning, and data processing applications
- Cost-effective option for users willing to handle complex installation and cooling requirements
Cons:
- Runs extremely hot and requires advanced cooling solutions like water cooling or active fans
- Difficult to install, often needing hardware modifications and driver configuration expertise
- Lacks video outputs and is primarily designed for server environments, limiting typical desktop use
M.2 Accelerator with Dual Edge TPU M.2-2230 (E-key)

The Coral M.2 Accelerator with Dual Edge TPU is ideal for users who need high-performance on-device inference without relying on internet connectivity. It features two Google Edge TPUs, each delivering 4 TOPS, for a total of 8 TOPS peak performance, perfect for running multiple models simultaneously or pipelining. Its compact size (2 x 2 inches) makes it suitable for desktop systems with PCIe Gen2 x1 slots, though compatibility can be tricky if your slot has limited lanes. Easy to install and configure, it’s well-suited for real-time vision tasks like robotics or embedded ML, providing fast, efficient inference while preserving data privacy.
Best For: users seeking high-performance, on-device ML inference for real-time computer vision, robotics, or embedded applications on desktop systems with available PCIe x1 slots.
Pros:
- Delivers a combined 8 TOPS peak performance with two Edge TPUs, enabling fast parallel model processing.
- Compact size (2 x 2 inches) ideal for desktop integration without occupying much space.
- Easy to install and configure, with positive user feedback on setup and operation.
Cons:
- Compatibility may be limited on systems with only a single PCIe lane or non-standard PCIe configurations.
- Not recommended for laptops or systems lacking PCIe x1 slots, restricting portability.
- Requires careful power supply considerations due to dual TPU setup and specific PCIe connections.
SOM Google Edge TPU ML Compute Accelerator

For developers seeking a compact, power-efficient solution to accelerate machine learning inference, the SOM Google Edge TPU ML Compute Accelerator offers an excellent choice. It integrates Google’s Edge TPU into a small, 2×2-inch module that connects via a standard half-mini PCIe slot, making it compatible with many systems, including Debian, Ubuntu, Windows 10, and both x86-64 and ARMv8 architectures. With a performance of 4 TOPS at just 0.5 watts per TOPS, it handles real-time vision models like MobileNet v2 at 400 FPS efficiently. Ideal for tasks like person detection, users praise its speed, though some face driver compatibility issues.
Best For: developers and system integrators seeking a compact, energy-efficient edge AI accelerator for real-time machine learning inference in various hardware environments.
Pros:
- High performance with 4 TOPS at only 0.5 watts per TOPS, enabling efficient real-time vision processing.
- Compact size (2×2 inches) and standard half-mini PCIe interface for easy integration into diverse systems.
- Supports popular operating systems and architectures, including Debian, Ubuntu, Windows 10, x86-64, and ARMv8.
Cons:
- Occasional driver compatibility issues, especially on newer Linux distributions, requiring troubleshooting.
- Need for adapters to connect to PCIe slots on some systems, adding cost and complexity.
- Variability in pricing and availability across different online and offline retailers.
MX3 M.2 AI Accelerator

If you’re seeking a compact, high-performance AI accelerator for machine vision tasks, the MX3 M.2 AI Accelerator by MemryX stands out. It’s designed to boost AI workloads on computers and Raspberry Pi 5 devices, offering exceptional speed and energy efficiency. With a PCIe M.2 form factor and compatibility across Windows and Linux, it easily integrates into existing setups. The device features SRAM memory and is optimized for demanding computer vision and inference tasks, making it ideal for industrial, robotics, and embedded applications. Supported by a holistic SDK, it simplifies development and deployment, providing a powerful yet compact solution for AI acceleration.
Best For: professionals and developers seeking a compact, high-performance AI accelerator to enhance machine vision, AI inference, and embedded applications on computers and Raspberry Pi 5 devices.
Pros:
- High-speed processing with energy-efficient architecture suitable for demanding AI workloads
- Compact M.2 form factor that easily integrates with existing systems and Raspberry Pi 5 via HAT
- Supported by a comprehensive SDK, simplifying development, deployment, and integration
Cons:
- Limited to single-processor setups, potentially restricting scalability for larger projects
- Compatibility primarily with Windows and Linux, which may limit use in other operating environments
- Market ranking around #4,982 suggests it is a niche product with a smaller user base compared to mainstream options
Coral G650-04686-01 PCIe M.2 Accelerator (Edge TPU)

The Coral G650-04686-01 PCIe M.2 Accelerator (Edge TPU) is an excellent choice for deploying high-speed, power-efficient machine learning inference at the edge. Its onboard Edge TPU coprocessor delivers 4 TOPS, handling complex models like MobileNet v2 at 400 FPS while consuming just 0.5 watts per TOPS. Designed for seamless integration with Debian Linux systems via a compatible slot, it simplifies deployment in existing environments. Supporting TensorFlow Lite models, it enables quick deployment without building from scratch. This card is ideal for edge applications demanding fast, energy-efficient inference, making it a top pick for those prioritizing performance and low power consumption.
Best For: AI developers and edge computing professionals seeking high-speed, energy-efficient machine learning inference solutions integrated with Linux systems.
Pros:
- Delivers 4 TOPS performance for complex ML models like MobileNet v2 at high frame rates.
- Extremely power-efficient at just 0.5 watts per TOPS, ideal for edge applications.
- Compatible with Debian Linux and TensorFlow Lite models, simplifying deployment.
Cons:
- Requires a compatible PCIe M.2 slot, limiting hardware options.
- Focused primarily on inference, not training or development.
- May necessitate technical expertise for installation and integration.
NVIDIA Tesla M10 Graphics Accelerator Card

The NVIDIA Tesla M10 Graphics Accelerator Card stands out as an ideal choice for enterprise data centers requiring high-memory capacity and efficient passive cooling. With 32GB of GDDR5 memory and PCIe 3.0 interface, it handles large-scale inference workloads effectively. Its passive cooling design guarantees quiet operation and reduces maintenance needs, making it suitable for dense server environments. Manufactured by Lanner and available since March 2021, it ranks well among graphics cards. While specific performance metrics aren’t highlighted, its high-memory capacity and cooling efficiency make it a reliable option for data centers prioritizing stability and scalability in inference tasks.
Best For: enterprise data centers seeking high-memory capacity and efficient passive cooling for large-scale inference workloads.
Pros:
- High 32GB GDDR5 memory suitable for demanding inference tasks
- Passive cooling design ensures quiet operation and low maintenance
- PCIe 3.0 interface provides reliable high-speed connectivity
Cons:
- Limited performance details beyond memory and cooling specifications
- No explicit technical benchmarks or performance metrics provided
- Availability and pricing may vary, requiring online or offline checks
NVIDIA Tesla L4 24GB PCIe Graphics Accelerator

Designed for large-scale AI and video inference workloads, the NVIDIA Tesla L4 24GB PCIe Graphics Accelerator delivers exceptional performance and energy efficiency. Its 24GB of video memory, fourth-generation Tensor Cores, and third-gen RT Cores enable fast AI, graphics, and vision AI acceleration. Optimized for edge deployments, it supports advanced video codecs like AV1 and DLSS 3, boosting generative AI and visual search tasks. With up to 99% better energy efficiency and a compact, low-profile design, the L4 reduces operational costs and environmental impact. It’s ideal for enterprises seeking scalable, high-performance inference solutions that balance speed, efficiency, and sustainability.
Best For: large enterprises and data centers seeking scalable, energy-efficient AI and video inference solutions for edge deployments and high-performance workloads.
Pros:
- High-performance with 24GB video memory and advanced Tensor and RT Cores for fast AI and graphics acceleration
- Exceptional energy efficiency, reducing operational costs and environmental impact by up to 99%
- Compact, low-profile design suitable for diverse deployment environments, including edge locations
Cons:
- Higher initial cost compared to traditional CPU infrastructure
- Limited to PCIe slot compatibility, requiring appropriate hardware setup
- Availability may vary due to market demand and release timing
nVidia Tesla K10 8GB GDDR5 PCIe Computing Accelerator

If you’re seeking a high-performance GPU for scientific computing or AI inference, the NVIDIA Tesla K10 8GB GDDR5 PCIe accelerator stands out with its dual Kepler GPUs delivering up to 4.5 TFLOPS. It features 8 GB of GDDR5 memory running at 6000 MHz, supporting resolutions up to 3840×2160. Designed for professional and server use, it excels in scientific tasks, AI experimentation, and rendering. While powerful, users report challenges with heat management and driver issues, especially with second-hand units. Its bulk purchase and lack of retail packaging make it more suitable for advanced users with proper cooling solutions, rather than casual or retail buyers.
Best For: advanced researchers and professionals needing high-performance GPU acceleration for scientific computing, AI experimentation, or rendering tasks in server or data center environments.
Pros:
- Delivers up to 4.5 TFLOPS of computational power suitable for demanding workloads
- Features 8 GB GDDR5 memory at 6000 MHz, supporting high-resolution outputs up to 3840×2160
- Designed for professional and server use with dual GK104 Kepler GPUs, optimizing high-performance tasks
Cons:
- Requires effective cooling solutions due to heat generation, which can be challenging to manage
- Driver issues and compatibility problems, especially with second-hand or damaged units, may affect performance
- Bulk purchase and lack of retail packaging make it less suitable for casual or retail buyers
NVIDIA Tesla P4 8GB GDDR5 Inferencing Accelerator

For organizations seeking a compact, energy-efficient inference accelerator, the NVIDIA Tesla P4 stands out due to its low-profile PCIe form factor and 8 GB GDDR5 memory. It delivers 22 TOPS (INT8), powered by Pascal architecture, optimizing deep learning inference with markedly reduced latency and enhanced energy efficiency—60 times better than CPUs. Its passive cooling design suits scale-out server deployments, though thermal throttling can occur without proper airflow. While it’s effective for speech recognition, visual search, and video recommendations, some users report overheating issues. Overall, the Tesla P4 offers a solid balance of compactness and performance, ideal for AI inference needs in constrained environments.
Best For: organizations seeking a compact, energy-efficient AI inference accelerator for scale-out server deployments in environments where thermal management is carefully maintained.
Pros:
- Compact low-profile PCIe form factor ideal for constrained spaces
- Significant reduction in inference latency and energy consumption compared to CPUs
- Passive cooling design suitable for scale-out server environments
Cons:
- Reports of overheating and thermal throttling without adequate airflow
- Mixed customer reviews indicating potential variability in unit quality
- Limited memory (8 GB) compared to newer alternatives like NVIDIA T4 with 16 GB
Hailo-8 M.2 AI Accelerator Module for Raspberry Pi 5

The Hailo-8 M.2 AI Accelerator Module stands out as an ideal choice for developers seeking high-performance edge AI processing with their Raspberry Pi 5. It features a 26 TOPS Hailo-8 processor, supporting standard AI frameworks like TensorFlow and ONNX, enabling real-time inferencing. Its PCIe Gen3, 4-lane interface guarantees fast data transfer, while the M.2 form factor and Raspberry Pi HAT+ compliance make installation straightforward. With a compact size, onboard power monitoring, and a wide operating temperature range, it’s built for demanding environments. Certified CE and FCC, it delivers efficient, low-latency AI inference suitable for scalable, edge AI applications.
Best For: developers and AI engineers seeking high-performance, low-latency edge AI solutions compatible with Raspberry Pi 5 for scalable and demanding applications.
Pros:
- Supports 26 TOPS Hailo-8 AI processor for powerful inference capabilities.
- Compatible with standard AI frameworks like TensorFlow, ONNX, and Pytorch for flexible deployment.
- Compact M.2 form factor with Raspberry Pi HAT+ compliance simplifies installation and integration.
Cons:
- Limited to a maximum power consumption of 8.65W, which may require adequate cooling in some environments.
- Proprietary components for certain AI frameworks could limit open-source flexibility.
- Customer ratings are modest at 4.0/5 based on limited reviews, indicating room for wider user feedback.
Coral Dual Edge TPU Adapter for Coral M.2 Accelerator

Looking to maximize AI inference performance with your Coral M.2 Accelerator modules? The Coral Dual Edge TPU Adapter is designed specifically for that purpose. It fits standard M.2 2280 B-key or M-key slots and supports PCIe Gen2 bandwidth, ensuring fast data transfer. This adapter is incompatible with SATA M.2 and Raspberry Pi CM4/USB enclosures, preventing user errors. It features a secure, vibration-resistant mounting with a stainless steel screw and provides dual PCIe lanes downstream for enhanced throughput. Overall, it’s an optimized, reliable solution for boosting inference speed in systems that support PCIe x1 Gen2 interfaces, making it a top choice for Coral M.2 accelerators.
Best For: AI developers and system integrators seeking to enhance inference performance with Coral M.2 Accelerators in PCIe-compatible setups.
Pros:
- Optimized for Coral M.2 Accelerator modules with Dual Edge TPU for maximum inference speed
- Supports bidirectional PCIe Gen2 bandwidth with dual lanes downstream for high data throughput
- Secure, vibration-resistant mounting with included stainless steel screw ensures reliable operation
Cons:
- Compatible only with M.2 2280 B-key or M-key slots supporting PCIe, not SATA or other M.2 types
- Not compatible with Raspberry Pi CM4 or USB enclosures, limiting use cases to specific hardware
- Requires PCIe x1 Gen2 slots, which may not be available on all systems
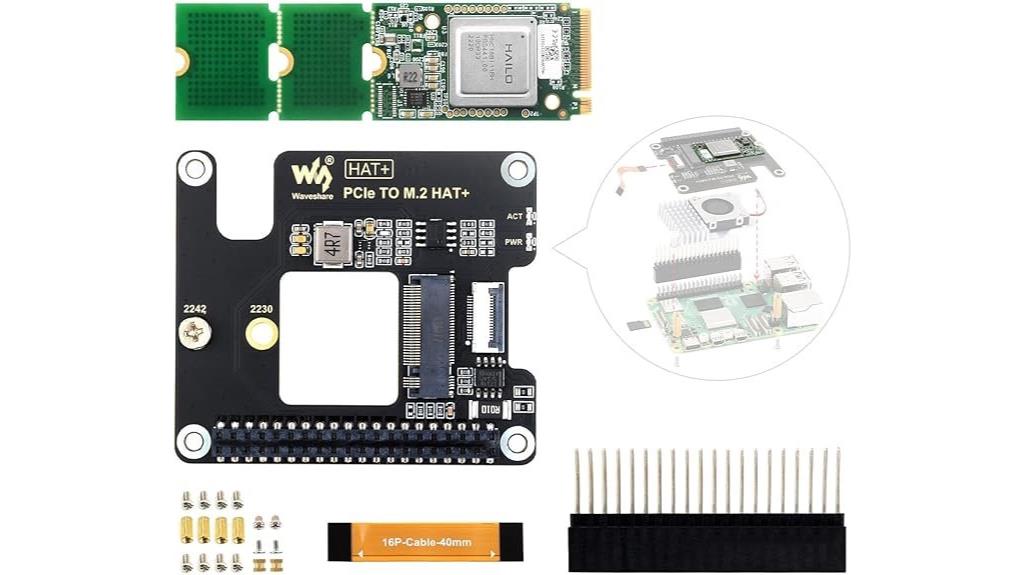
If you need a compact, high-performance AI accelerator for edge inference, the Waveshare Hailo-8 M.2 AI Accelerator Module with PCIe Adapter is an excellent choice. It’s compatible with Raspberry Pi 5 and supports Linux and Windows, making integration straightforward. Powered by the Hailo-8 processor with 26 TOPS, it delivers real-time, low-latency processing ideal for vision tasks like object detection. With energy efficiency at around 2.5W, it supports frameworks like TensorFlow, ONNX, and Pytorch. Its scalable design handles multi-stream and multi-model workloads, making it suitable for demanding edge AI applications.
Best For: edge AI developers and vision application engineers seeking a compact, high-performance inference accelerator compatible with Raspberry Pi 5 and supporting popular frameworks.
Pros:
- High processing power with 26 TOPS Hailo-8 AI processor enabling real-time inference
- Energy-efficient design consuming approximately 2.5W, suitable for edge deployment
- Supports multiple AI frameworks like TensorFlow, ONNX, Pytorch, facilitating versatile development
Cons:
- Customer reviews indicate some detection and setup challenges, potentially requiring troubleshooting
- Limited to vision tasks; not suitable for generative AI applications like Hailo-10H
- Slightly higher price point and limited initial availability may affect accessibility
NVIDIA Tesla A100 Ampere 40 GB Graphics Processor Accelerator

For professionals seeking high-performance GPU acceleration for AI inference and data analytics, the NVIDIA Tesla A100 Ampere 40 GB stands out with its advanced Tensor Core technology and scalable architecture. It connects via PCIe 4.0 x16, offering 40 GB of memory and support for large-scale workloads. Its Multi-Instance GPU (MIG) technology allows partitioning into seven instances, maximizing resource utilization. Designed for data centers, it excels in AI, HPC, and analytics tasks. However, customer reviews highlight issues like overheating and support limitations, which can impact reliability. Despite some concerns, its raw performance and flexibility make it a compelling choice for demanding inference workloads.
Best For: professionals needing high-performance GPU acceleration for AI inference, data analytics, and HPC workloads in data center environments.
Pros:
- Scalable architecture with Multi-Instance GPU (MIG) technology for flexible workload management
- Advanced third-generation Tensor Cores for fast, efficient processing across precisions
- Supports large-scale deployment with high memory capacity of 40 GB
Cons:
- Customer reviews report overheating issues without workload and limited support from manufacturers
- Performance can vary significantly, with some users experiencing low FPS or detection failures
- Lack of manufacturer warranty beyond six months and support limitations from third-party sellers
SunFounder Dual NVMe Raft for Raspberry Pi 5, PCIe Gen 2.0 to M.2 HAT

The SunFounder Dual NVMe Raft for Raspberry Pi 5 is an excellent choice for makers and developers seeking to transform their Raspberry Pi 5 into a high-performance storage and AI platform. It adds two M.2 slots supporting PCIe Gen 2.0, delivering up to 500MB/s per slot, perfect for RAID setups or pairing with Hailo-8L AI accelerators for real-time AI tasks. Compatible with multiple Raspberry Pi 5 models, it’s ideal for NAS, media centers, or edge AI projects. The kit includes all necessary cables, screws, and a detailed guide, making installation straightforward even for beginners. SunFounder’s support and tutorials guarantee a smooth setup process.
Best For: makers, AI developers, and NAS enthusiasts seeking to upgrade their Raspberry Pi 5 with high-speed storage and real-time AI capabilities.
Pros:
- Supports dual NVMe SSDs with PCIe Gen 2.0 for fast data transfer up to 500MB/s per slot
- Compatible with various Raspberry Pi 5 models, expanding storage and AI project possibilities
- Comes with comprehensive accessories and detailed installation guides for beginner-friendly setup
Cons:
- Not compatible with Pironman Series, limiting hardware options for some users
- Requires careful handling during installation due to sensitive PCIe and M.2 components
- Limited to PCIe Gen 2.0 speeds, which may be slower compared to newer PCIe standards
Factors to Consider When Choosing Pci-E Accelerator Cards for Inference

When choosing a PCIe accelerator card for inference, I concentrate on compatibility with my system’s hardware and power supply requirements to guarantee smooth operation. I also evaluate cooling options to keep the card functioning efficiently and review performance benchmarks to satisfy my workload demands. Finally, I verify the card’s physical dimensions and slot needs to confirm it fits properly in my setup.
Compatibility With Systems
Choosing a PCIe accelerator card that fits your system requires careful attention to compatibility factors. First, verify the card’s PCIe interface matches your motherboard’s slot version, whether it’s 3.0, 4.0, or 2.0, to guarantee maximum performance. Check that the card’s form factor—like PCIe x16, M.2, or mini PCIe—physically fits within your chassis and available slots. You also need to confirm your motherboard supports the required number of PCIe lanes to avoid bandwidth limitations. Additionally, confirm your power supply can deliver sufficient wattage and the necessary connectors. Finally, verify your operating system and driver support are compatible with the accelerator, enabling smooth operation and reliable inference. Compatibility is key to getting the most out of your investment.
Power Supply Requirements
Making sure your power supply can handle the demands of PCIe accelerator cards is essential for stable operation. Many high-performance accelerators, like the Tesla K80 or A100, can draw over 200W, so your power supply must provide enough wattage. Check that your system’s power connectors—6-pin or 8-pin PCIe cables—match the card’s requirements to avoid power issues or damage. When deploying multiple accelerators, consider the total power consumption per TOPS or TFLOP to estimate your system’s needs. Low-power modules, such as M.2 or Coral Edge TPU, usually need less than 5W and can draw power directly from the PCIe slot or dedicated connectors. To conclude, ensure your PSU’s efficiency and headroom are sufficient to handle peak loads, preventing crashes during intensive inference tasks.
Cooling Solutions Needed
Effective cooling solutions are essential for maintaining the performance and longevity of PCIe accelerator cards during inference workloads. High-performance cards, especially those with multiple GPUs or high power demands, generate significant heat that must be efficiently dissipated. Without proper cooling, thermal throttling can occur, reducing speed and accuracy, and risking hardware failure. Active fans, water cooling, and heatsinks are common options, but compatibility is critical. Check if your system case or server chassis provides enough space and airflow to support these cooling methods. Proper thermal management not only safeguards your hardware but also ensures consistent, ideal inference performance. Investing in robust cooling is indispensable for maximizing both hardware lifespan and inference efficiency in demanding AI workloads.
Performance Benchmarks
When selecting PCIe accelerator cards for inference, understanding performance benchmarks helps you compare different options effectively. These benchmarks often measure throughput in TOPS, such as 4 TOPS for Edge TPUs or 26 TOPS for Hailo-8 modules, indicating raw processing power. Frame rates, like MobileNet v2 running at 400 FPS, reveal real-time performance potential. Latency metrics are also critical; lower latency means faster inference, essential for time-sensitive applications. Power efficiency is assessed through performance-per-watt ratios, such as 2 TOPS per watt, balancing speed and energy consumption. Keep in mind that real-world performance varies with model complexity and hardware setup, so referencing standardized datasets and testing conditions is crucial for accurate comparison. These benchmarks give a clearer picture of each card’s capabilities.
Physical Dimensions & Slots
Choosing the right PCIe accelerator card starts with understanding its physical dimensions and slot requirements. The length, width, and height of a card determine if it fits your case and motherboard. Some cards are compact, like M.2 or mini PCIe, ideal for small form factors or embedded systems. It’s vital to match the card’s interface—such as x1, x4, x8, or x16—with your motherboard’s PCIe slots to guarantee proper installation and performance. Compatibility also depends on keying (B, M, or B+M) and supporting the correct PCIe version, like Gen3 or Gen4. Larger, high-performance cards may need multiple slots and ample clearance. Carefully checking these dimensions and slot types helps avoid installation issues and guarantees your setup runs smoothly.
Software & Driver Support
Ensuring your PCIe accelerator card integrates smoothly with your system involves more than just checking physical fit and slot compatibility. You need to verify that the card supports your operating system, whether it’s Linux, Windows, or a specialized embedded system. It’s essential to confirm that the manufacturer offers up-to-date drivers and software libraries compatible with frameworks like TensorFlow Lite, PyTorch, or ONNX. Driver stability is equally important; review user feedback and community forums to gauge reliability, especially for newer or less common hardware. Additionally, a straightforward, well-documented installation process can save you time and frustration. Finally, consider the availability of software tools and APIs that simplify model deployment, optimization, and management—these are vital for efficient inference workflows.
Frequently Asked Questions
How Do PCIE Version and Bandwidth Affect Inference Performance?
PCIe version and bandwidth directly impact inference performance by determining how quickly data moves between my accelerator card and the rest of my system. Higher PCIe versions, like 4.0 or 5.0, offer increased bandwidth, reducing bottlenecks. This faster data transfer allows my inference tasks to run more smoothly and efficiently, especially with large models or high-throughput workloads, ultimately boosting overall speed and responsiveness.
Are Specific AI Frameworks Optimized for Certain PCIE Accelerator Cards?
While some AI frameworks are optimized for specific hardware, I’ve found that most now support a wide range of PCIe accelerator cards, ensuring flexibility. Frameworks like TensorFlow and PyTorch often have tailored drivers or libraries, but they also adapt quickly to new hardware. So, even if a card isn’t explicitly optimized, I can usually get good performance by using compatible drivers and software updates.
What Are Compatibility Considerations With Different Server or Embedded Systems?
When considering compatibility with different server or embedded systems, I always check the PCIe version and slot type to make certain proper fit. I also verify power supply requirements and physical dimensions to avoid fitting issues. Additionally, I confirm that the system’s BIOS and firmware support the accelerator card. Compatibility isn’t just about hardware; I also review driver support and software integration to ensure smooth operation.
How Does Power Consumption Influence Accelerator Card Selection?
Power consumption heavily influences my choice of accelerator cards because I want efficiency, reliability, and cost-effectiveness. I look for cards that deliver high performance without draining too much power, which helps reduce cooling needs and energy costs. I also consider thermal management and the potential impact on overall system stability. Balancing wattage with performance guarantees I get the speed I need without sacrificing energy efficiency or increasing operational expenses.
Can Multiple PCIE Accelerators Be Combined for Parallel Inference?
Yes, I can combine multiple PCIe accelerators for parallel inference, which boosts overall performance and reduces latency. I make sure my system supports multi-GPU setups and uses software that handles workload distribution effectively. Proper configuration and synchronization are key to maximizing efficiency. Combining accelerators can be complex, but with the right hardware and software, I see significant gains in inference speed and throughput.
Conclusion
After exploring these top PCIe accelerator cards, I believe that choosing the right one truly depends on your specific needs and setup. It’s tempting to think that the most powerful GPU always wins, but sometimes a specialized accelerator like the Coral Mini or Hailo-8 can outperform traditional GPUs in efficiency. Just like a good theory, the best card proves that matching the tool to the task is what really drives speed and innovation.







